Introduction to Large Language Models (LLMs)
Objectives
Understand why the filed of language modeling needed LLMs.
Explore what LLMs are.
Understand how do LLMs differ from other machine learning approaches.
Language modeling (LM)
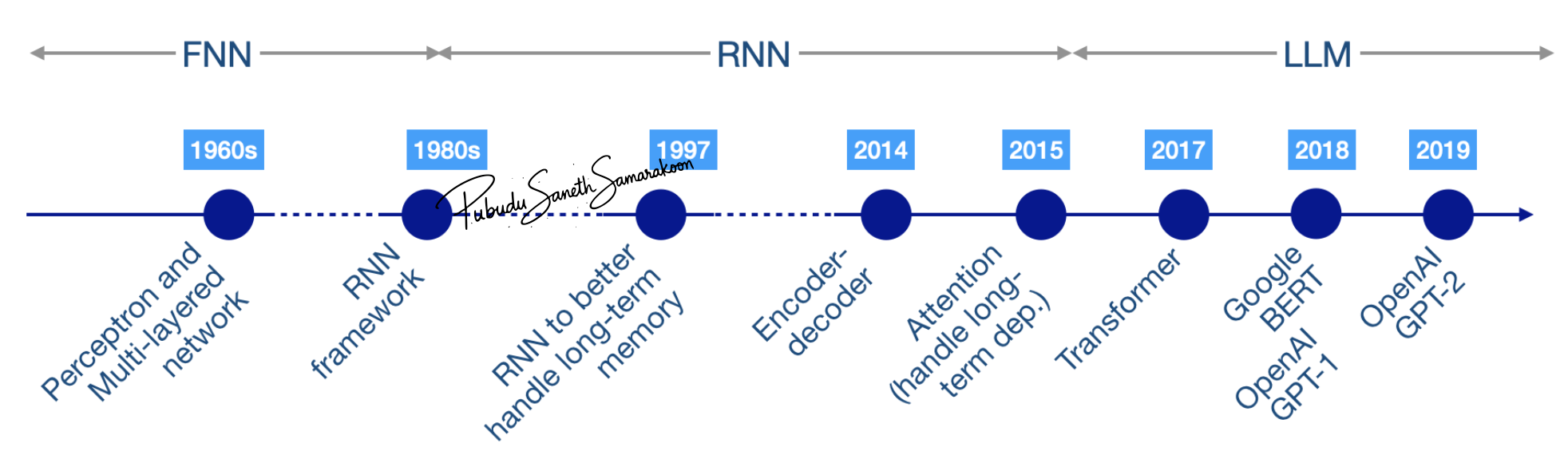
LM was introduced in early 1980s with the introduction of Recurrent Neural Networks (RNNs)
With the advances in the field of LM, more advance techniques to RNNs were introduced to
preserve gradients and maintain information (1997-2014; Gating mechanisms)
handle long-term memory (2015; Attention for RNNs)
manage variable-length input output sequences (2014; Encoder-decoder for RNNs)
Why does the LM field needs LLMs?
RNNs process inputs sequentially and the attention mechanism was not build into the core architecture
RNNs are slow and lead to scalability challenges
Transformer technology introduced in the paper “Attention Is All You Need” addressed this limitations in Modern RNNs
Transformer technology (therefore LLMs) eliminate sequential dependency:
all positions can be computed in parallel
Scalable model training and inference
LLMs
Transformer-based neural networks with large number of parameters (billions to trillions) that employ self-attention mechanisms and trained on vast amounts data (billions to trillions of tokens)
LLMs vs other ML approaches
Behavior of traditional ML approaches are specifically tied to the training objectives
LLMs exhibits capabilities that were not explicitly trained
i.e., Simple training objectives lead to complex capabilities
e.g., LLM’s ability to translate despite never being specifically trained for translation
These capabilities are referred “Emergent Behavior” of LLMs
This complexity emerges from:
Large scale + rich data + powerful architecture
Emergent mechanism is still not fully understood
Anatomy of a LLM
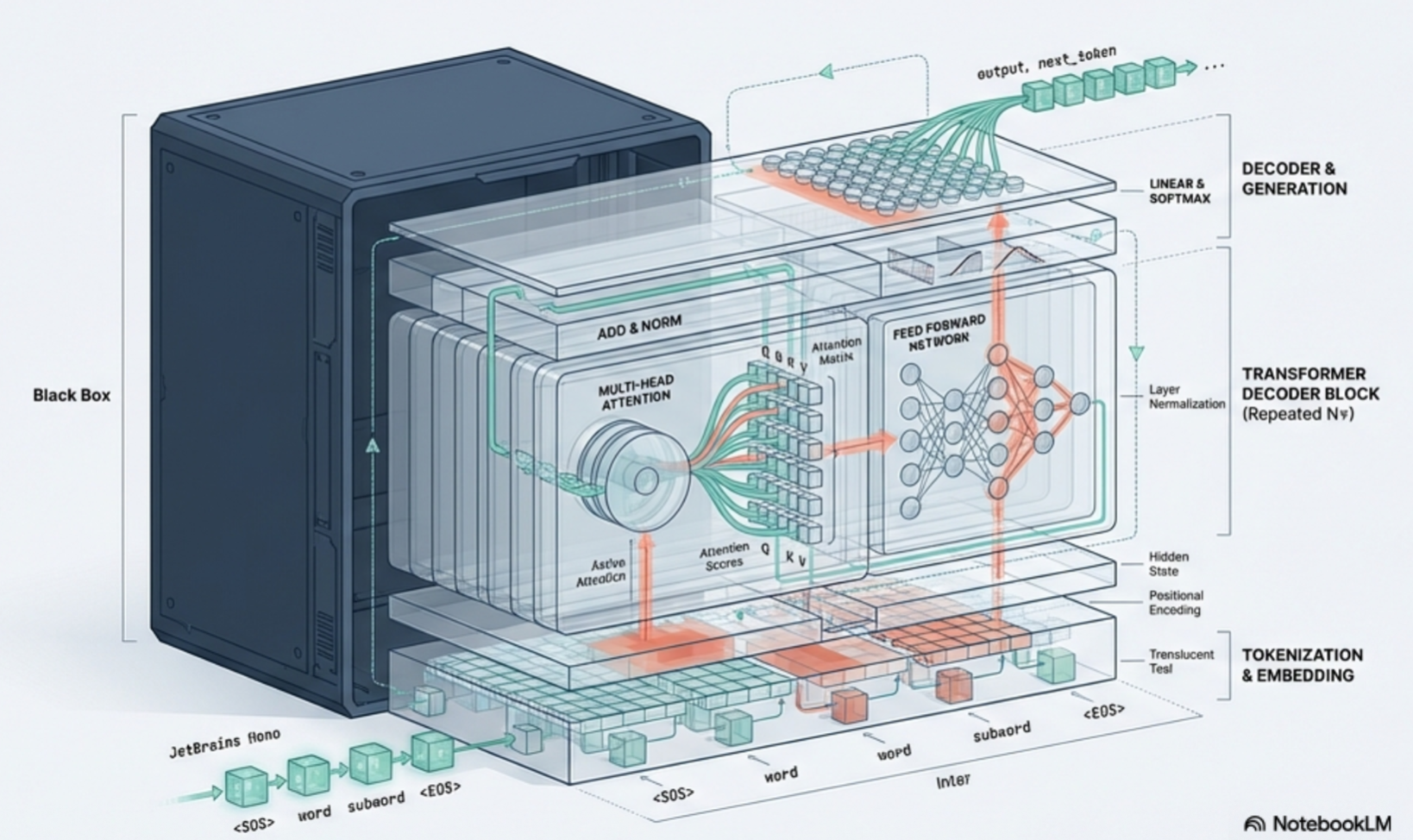
Tokenizer
Embedding layer
Transformer block
Self-attention layer
Feedforward neural network
Language modeling head (LM head)