Introduction to embedding
Objectives
Understand what embedding is and why it is important
Explore how embedding layers in LLMs process tokens
Token embedding
What is token embedding?
Token embedding is the process of converting discrete tokens (specifically token-IDs) into vectors
These vectors can be represented in a high-dimensional space
Token ID -> vector with length
N(points in N-dimensional space)
Representing tokens in a high-dimensional space enables to effectively capture complex patterns and relationships
What token embedding is important?
Token-IDs are just arbitrary integers assigned during tokenization that do not have mathematical relationship between these integers
Tokens are discrete numerical labels with no geometric or relational structure
Token embedding convert these numerical labels to structured representations - vectors (points in a high-dimensional space) in a way that captures the relationships between tokens
In this high-dimensional space, semantically related tokens like “dog”, “cat”, “animal” cluster together
This structure is learned during model training process so that words with similar contextual roles have similar vector representations (similarity between vectors represent relationships between tokens)
Demo
Explore token embeddings (Word2Vec embeddings):
Word2Vec embedding was widely used before the introduction of LLM technology
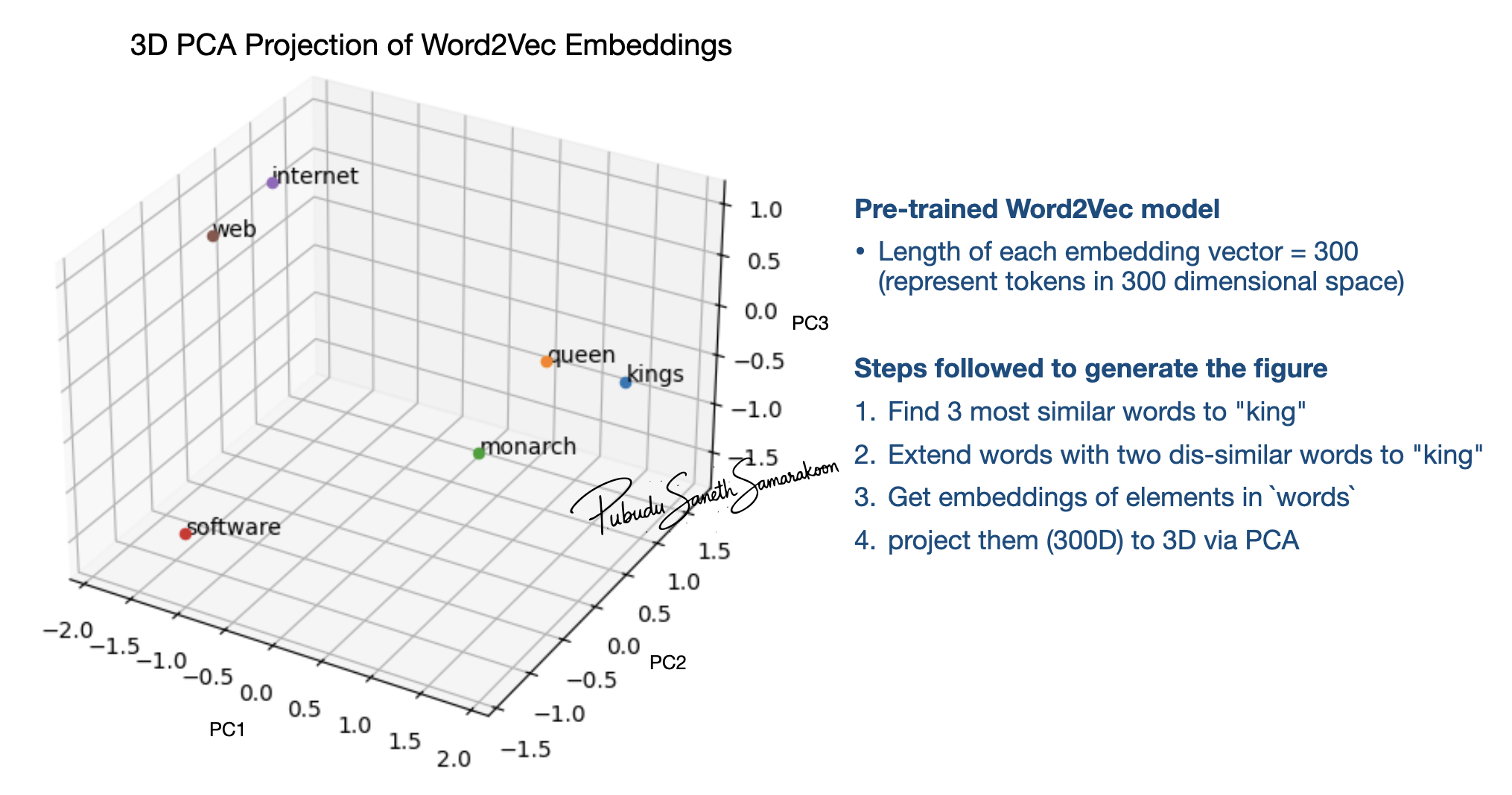 Figure shows that the words with similar roles in natural language cluster together when represented in high-dimensional space
Figure shows that the words with similar roles in natural language cluster together when represented in high-dimensional space
Python implementation
import gensim.downloader as api
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# Download and load the pre-trained Google News model
wv = api.load('word2vec-google-news-300')
print(f"Dimensions of 'king' embeddings: {wv['king'].shape}")
print(f"First 10 elements of 'king' embeddings: {wv['king'][:10]}")
similar_words = wv.most_similar('king', topn=3)
[print(f"{word}: {similarity:.4f}")for word, similarity in similar_words]
print(similar_words)
def get_3d_projections(word_list, wv):
# Extract embeddings for the given words
print("Word List:", word_list)
embeddings = [wv[word] for word in word_list]
# Apply PCA to reduce dimensions to 3D
pca = PCA(n_components=3)
projections = pca.fit_transform(embeddings)
return projections
def plot_3d_projections(projections, words):
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
for i, word in enumerate(words):
x, y, z = projections[i]
ax.scatter(x, y, z, label=word)
ax.text(x, y, z, word, fontsize=10)
ax.set_title("3D PCA Projection of Word2Vec Embeddings")
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_zlabel("PC3")
#plt.legend(loc='upper left')
#plt.tight_layout()
plt.show()
words = [word for word, _ in similar_words]
words.extend(["software", "internet", "web" ])
reduced_embeddings = get_3d_projections(words, wv)
plot_3d_projections(reduced_embeddings, words)
Token embeddings in LLMs
Tokenizer in GPT-2 smallest model has a vocabulary of 50257 tokens
This GPT-2 tokenizer maps tokens to integers 0-50256 with no mathematical relationship in those assignments
For example, tokenizer maps input -
cat sat on theto tokens[9246, 3332, 319, 262]that do not have inherent relationship between these numbers themselvesToken embeddings convert these arbitrary Token-IDs into dense vectors in a continuous space of 768 dimensions
Now
cat sat on thearen’t just different numbers—they’re points in a high-dimensional space where the similarity between vectors has meaningCapturing semantic meaning through token embeddings is learned during LLM pre-training process (detailed later)
GPT-2 Token embeddings: Step-by-Step Breakdown
Initiate a learnable matrix (dimensions
[vocab_size × embedding_dim])Each row represents one token’s embedding vector
Initiate the matrix with small random values (e.g., -2.84 to 1.58) to break symmetry
if all embeddings were identical, tokens couldn’t differentiate during training
As the model processes training examples, it makes predictions using these random embeddings
Prediction errors generate gradients that flow back through the network to the embedding layer
Token embeddings are optimize through backpropagation (Tokens appearing in similar contexts receive similar updates)
Through thousands of iterations in the pre-training process, random vectors evolve into meaningful representations where “cat” and “dog” cluster together
The final optimized embeddings encode semantic relationships learned entirely from the training data patterns
Explore LLM token embeddings
Embedding Dimensions:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gpt2",)
# Access the word token embedding layer
wte = model.transformer.wte
# Get vocabulary size and embedding dimension
print(f"Vocabulary Size: {wte.num_embeddings}; Embedding Dimension: {wte.embedding_dim}")
# The embedding matrix is stored in the 'weight' attribute
print(f"Shape of the embedding matrix: {wte.weight.shape}")
LLM Embedding of made-up words:
text_rand = "rand_xyz"
rand_token_ids = tokenizer.encode(text_rand)
print(f"Token IDs for text '{text_rand}': {rand_token_ids}")
print(f"Decoded text: {tokenizer.decode(rand_token_ids)}")
print()
# Use evaluation mode and not gradient calculation (training)
with torch.no_grad():
rand_token_embeddings = wte(torch.tensor(rand_token_ids))
print(f"Shape of the random token embeddings: {rand_token_embeddings.shape}")
print()
for i in range(len(rand_token_ids)):
print(f"Token {i}: {tokenizer.decode(rand_token_ids[i])} -> {rand_token_ids[i]};\n\tEmbeddings (first 5): {rand_token_embeddings[i][:5]}")
Output
Embedding Dimensions
Vocabulary Size: 50257; Embedding Dimension: 768
Shape of the embedding matrix: torch.Size([50257, 768])
LLM Embedding of made-up words
Token IDs for text 'rand_xyz': [25192, 62, 5431, 89]
Decoded text: rand_xyz
Shape of the random token embeddings: torch.Size([4, 768])
Token 0: rand -> 25192;
Embeddings (first 5D): tensor([-0.0456, -0.1112, 0.2527, 0.0098, -0.0464])
Token 1: _ -> 62;
Embeddings (first 5D): tensor([-0.0073, -0.0894, 0.0005, 0.0701, -0.0090])
Token 2: xy -> 5431;
Embeddings (first 5): tensor([-0.1123, -0.0957, 0.1115, -0.0743, 0.0958])
Token 3: z -> 89;
Embeddings (first 5D): tensor([-0.0141, -0.0427, 0.0941, -0.1052, 0.0594])
Position embeddings
Token embeddings process (converting unstructured token-ids to dense vectors) help capture relationships between tokens
Token embeddings process treats all positions equally
Token embedding alone makes models unable to distinguish token order without position information
Unable to distinguish between “dog bites man” and “man bites dog”
Position embeddings injects position information to embedding vectors
Embedding layer of LLMs
Token embeddings convert discrete token IDs into vector representations through a learnable matrix
Positional embeddings added to inject sequence order information to LLM embeddings
Embedding vectors (combined token and position embeddings) are parses to the next layer of the LLM - transformer layer/block
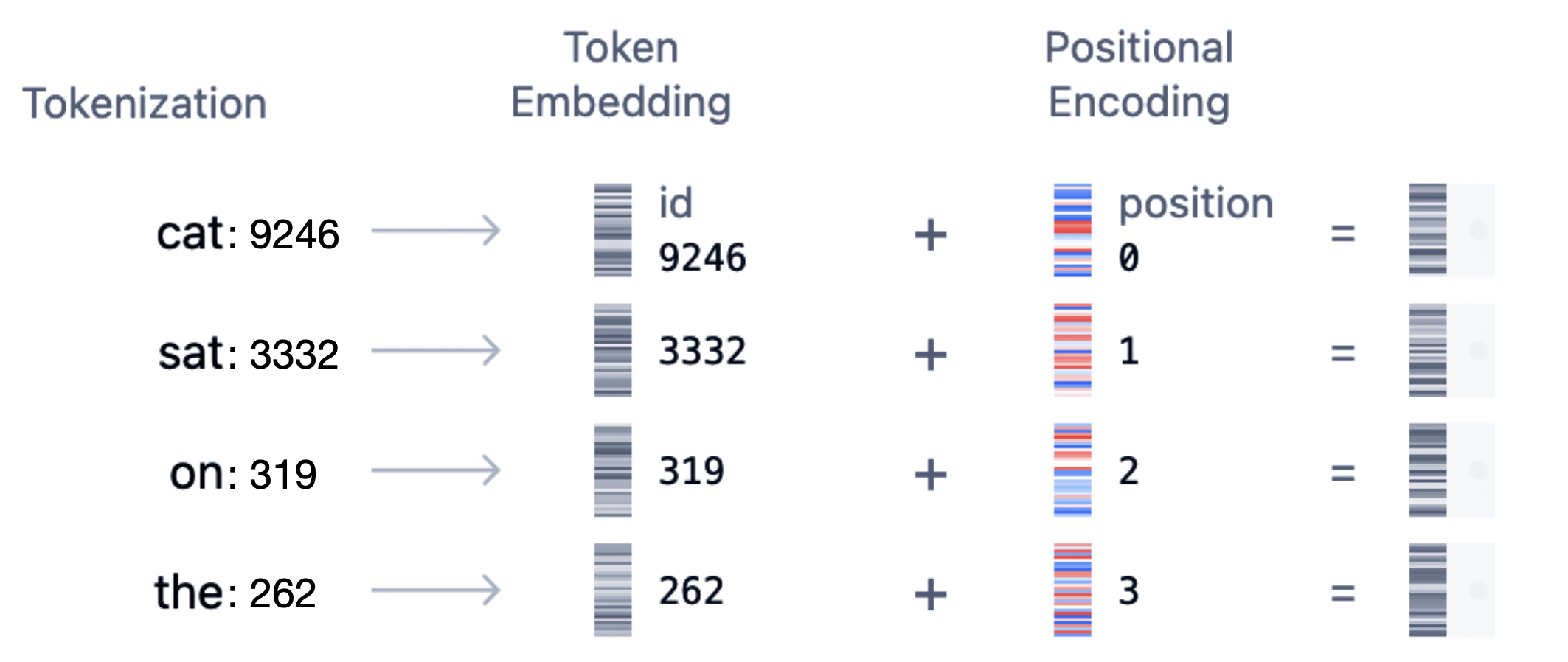
Source: transformer-explainer
Demo
Token and position embeddings:
Steps in the following script:
Tokenize input text
bank is near the river bankPass input to token and position embeddings
Calculate the similarity between 1st and last token
import torch
text_1 = "bank is near the river bank"
token_ids = tokenizer.encode(text_1)
for i in range(0,len(token_ids)):
print(f"Token {i}: {tokenizer.decode(token_ids[i])} -> {token_ids[i]}")
wte = model.transformer.wte # Token embedding
wpe = model.transformer.wpe # Position embedding
bank_1_id = token_ids[0]
wte_bank_1 = wte(torch.tensor(bank_1_id))
wpe_bank_1 = wpe(torch.tensor(0))
bank_2_id = token_ids[-1]
wte_bank_2 = wte(torch.tensor(bank_2_id))
wpe_bank_2 = wpe(torch.tensor(1))
cosine_sim = torch.nn.functional.cosine_similarity(
wte_bank_1 + wpe_bank_1,
wte_bank_2 + wpe_bank_2,
dim=0
)
print(f"Similarity: {cosine_sim.item():<.4f}") # Less than 1.0 - they're different!
The contextualization happens through the Transformer layers of the LLM by updating vector embeddings
Transformer update vectors from embedding layer to reflect the attention patterns that capture semantic relationships like “river” → “bank” (as in riverbank)
Output
LLM Embedding
## Notice the token 0 - "bank" and " bank" (with leading space)
Token 0: bank -> 17796
Token 1: is -> 318
Token 2: near -> 1474
Token 3: the -> 262
Token 4: river -> 7850
Token 5: bank -> 3331
Similarity: 0.5472