Masked Attention
Objectives
Understand what masked Self-Attention is and how it is applied
What is Masked Self-Attention?
Mechanism specific to the decoder blocks of a Transformer (like GPT).
Restricts the model’s to “only pay attention to previous token embeddings” when it is processing a specific token in the sequence
Masks model’s ability to pay to any future token embeddings
Why is it Important?
Without mask |
With mask |
|
|---|---|---|
Attention mechanism |
Exposed to future tokens |
Not exposed to future tokens |
Training & Inference |
Attend to future tokens |
Predict future tokens |
Prevents “Cheating” During Training
During training, model should learn how to predict the next token without “peeking” into the future
Masked attention ensures the model relies solely on the past to predict the future
Autoregressive text generation
Key to enable sequential generation autoregressive text generation (predicting the next word)
Forces the model to generate text one token at a time without peaking into the future tokens (model predicts the next word based only on past context)
Autoregressive text generation continues by feeding the output of one step as the input for the next, which is essential for creating coherent sentences.
Masking during the attention mechanism
When is the mask applied?
Mask is applied to scaled attention scores
Masked attention scores are used in the Softmax function
Ensure that the scaled attention scores sums to 1 over a restricted set of tokens
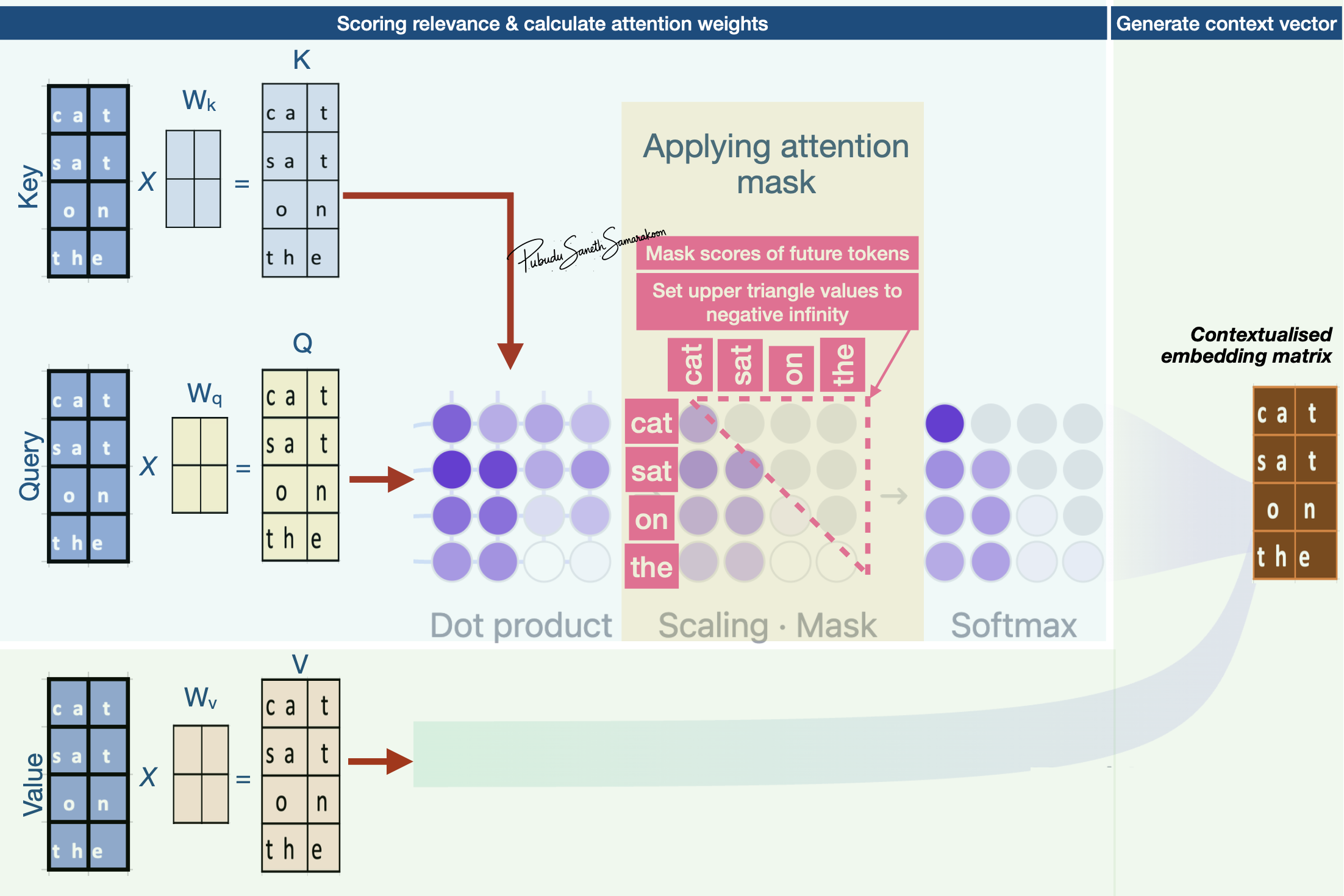
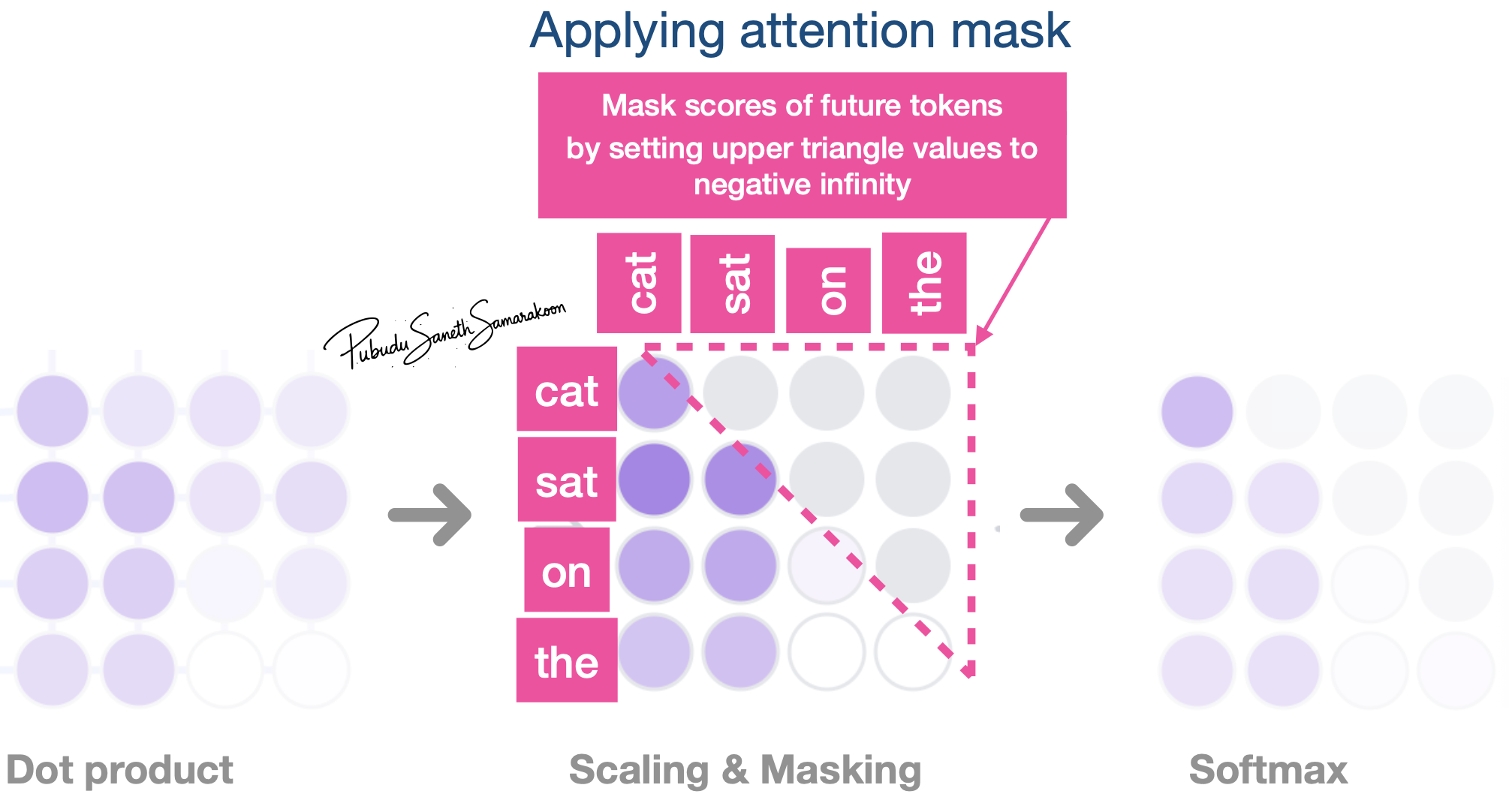
How to apply attention mask?
Mask: Set upper triangle values of the attention matrix to negative infinity
\(softmax(\frac{QK^T}{\sqrt{d_k}} + M)*V\)
Important
Causal Attention (Causal Masking)
In decoder transformer models like GPT:
Setting upper triangle values of the attention matrix to negative infinity is referred as Causal Attention (Causal Masking)
Causal Attention describes the behavioral constraint
Model must be causal, i.e., respect the sequence of tokens as they appear in time
Masked Attention describes the technical implementation
Model uses a mathematical mask (upper triangle of matrix with negative infinity)
Warning
Masking is a broader term
“Mask” can be applied to tokens for reasons unrelated to causality
Padding Masks:
Ignoring filler words (Used to ignore ‘[PAD]’ tokens)
Used in both encoder and decoder transformers
Masked Language Modeling:
Models like BERT use “Masked Language Modeling” to hide random words in the middle of a sentence to force the model to guess them
Masking process: Replace a small percentage (e.g., 15%) of input tokens with a special [MASK] token
Objective: To teach the model to understand the relationship between words by “filling in the blanks”