Multi-head self-attention
Objectives
Understand what Multi-head self-attention is and why it is important
Explore how it implemented in a transformer block
What is Multi-head attention
Multi-head attention divides the attention process into multiple independent parallel instances
Each parallel processes is called an “attention head”
Extend attention mechanism to multiple parallel processes
Why is it important?
Independent parallel attention heads allow the model to focus on different aspects of the input simultaneously
Help model recognize more intricate and nuanced patterns in the text than a single-head attention mechanism
E.g., One head might capture grammatical structure while another captures semantic meaning
Multi-head attention mechanism
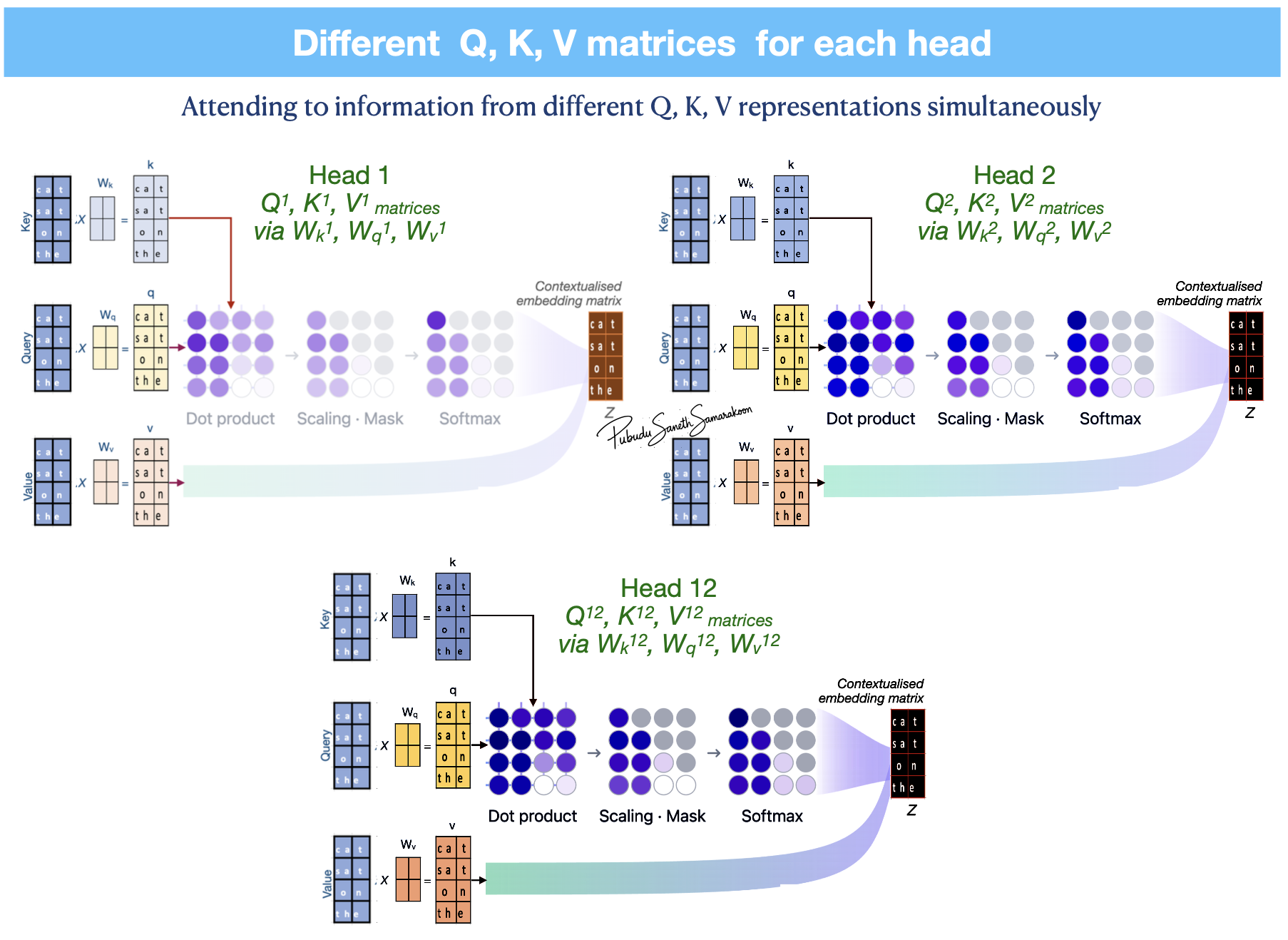
Independent Projections using multiple sets of learnable weight matrices (\(W_{q}\), \(W_{k}\), \(W_{v}\)) creates distinct Query, Key, and Value matrices for each head
Each head executes attention mechanism in parallel generate multiple context vectors
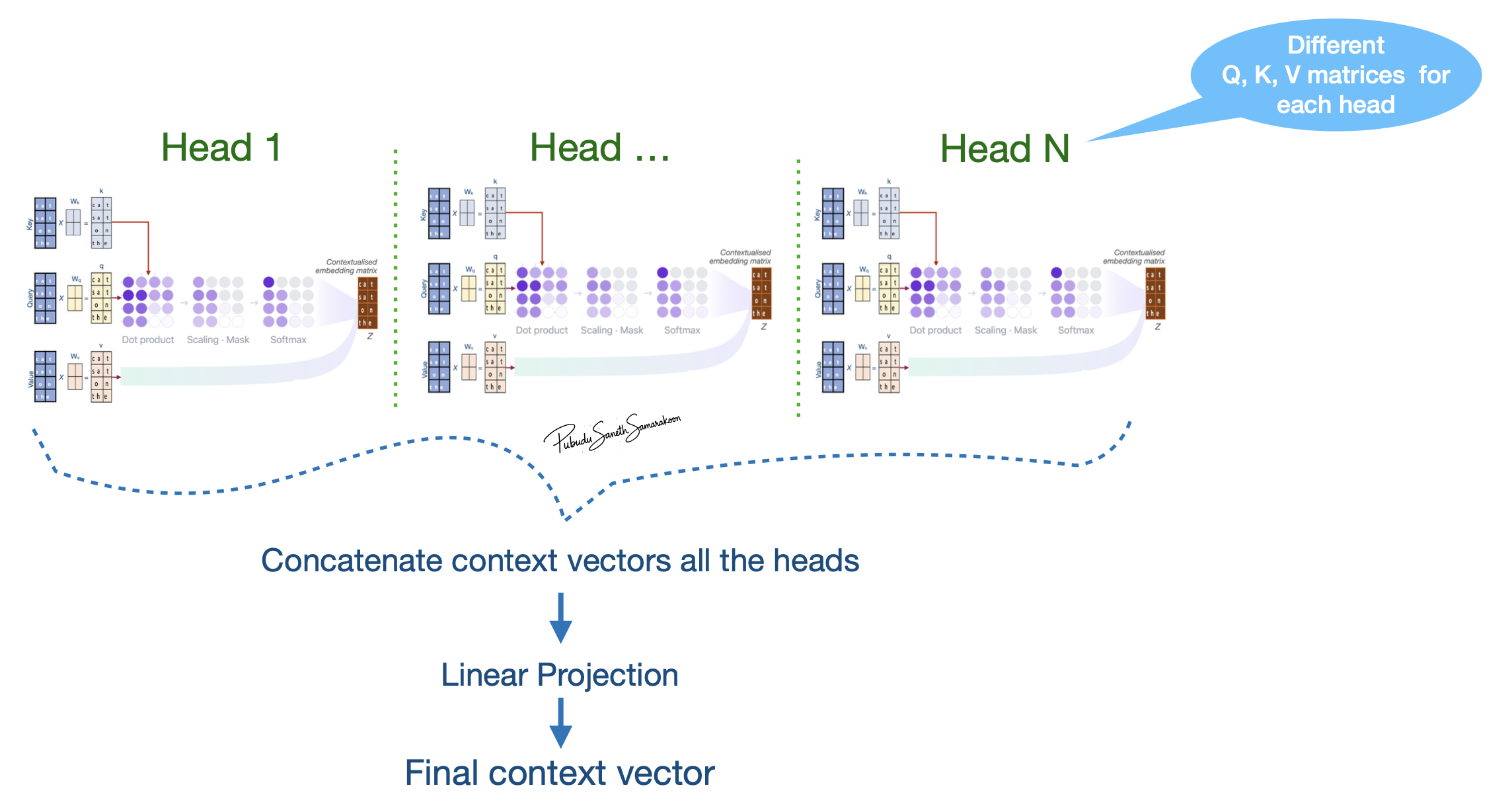
Concatenation:
The output vectors from all the parallel heads are joined (concatenated) together to form a single, longer vector
Final Linear Projection:
Combine the information from all heads into the final output dimension required by the next layer
Note
In efficient implementations, rather than literally stacking separate layers, Multi-head attention is often achieved by projecting the input into a large dimension and then mathematically “splitting” it into heads for processing