Introduction to tokenization
Objectives
Explore what tokenization is and why it is important.
Understand how tokenizer process its input text
Tokenizers
What is tokenization?
Tokenizers take text as input and generate a sequence of integer representations of input text
Why it is important?
This serves as the foundation for converting text to numerical representations that deep learning models can process
Tokenizers: Text to sub-word units (tokens)
Tokenizers process these input text by converting them into discrete sub-word units
i.e, Split input test in to discrete sub-word units
These “discrete sub-word units” are tokens
Token are mapped to corresponding Token IDs using the model vocabulary
Tokenization step-by-step
Tokenizer accepts text
cat sat on theas inputSplit test into tokens:
cat,sat,on,theTokenizer split text into sub-words (tokens). In this case, sub-words from the tokenizer are equal to words in the text
Tokenizer uses model’s vocabulary as a lookup table to map tokens to token-IDs (integer IDs)
Vocabulary: A dictionary of unique tokens and unique numerical identifiers assigned to each token (Token ID)
This provides a consistent mapping system that converts variable-length text into fixed numerical representations
Return corresponding token-IDs of the tokens from input text
Vocabulary is build from training data by mapping each unique token to a token ID, with special tokens added to handle unknown words and document boundaries, enabling LLMs to process diverse text inputs effectively. The vocabulary size is managed to balance expressiveness with computational efficiency
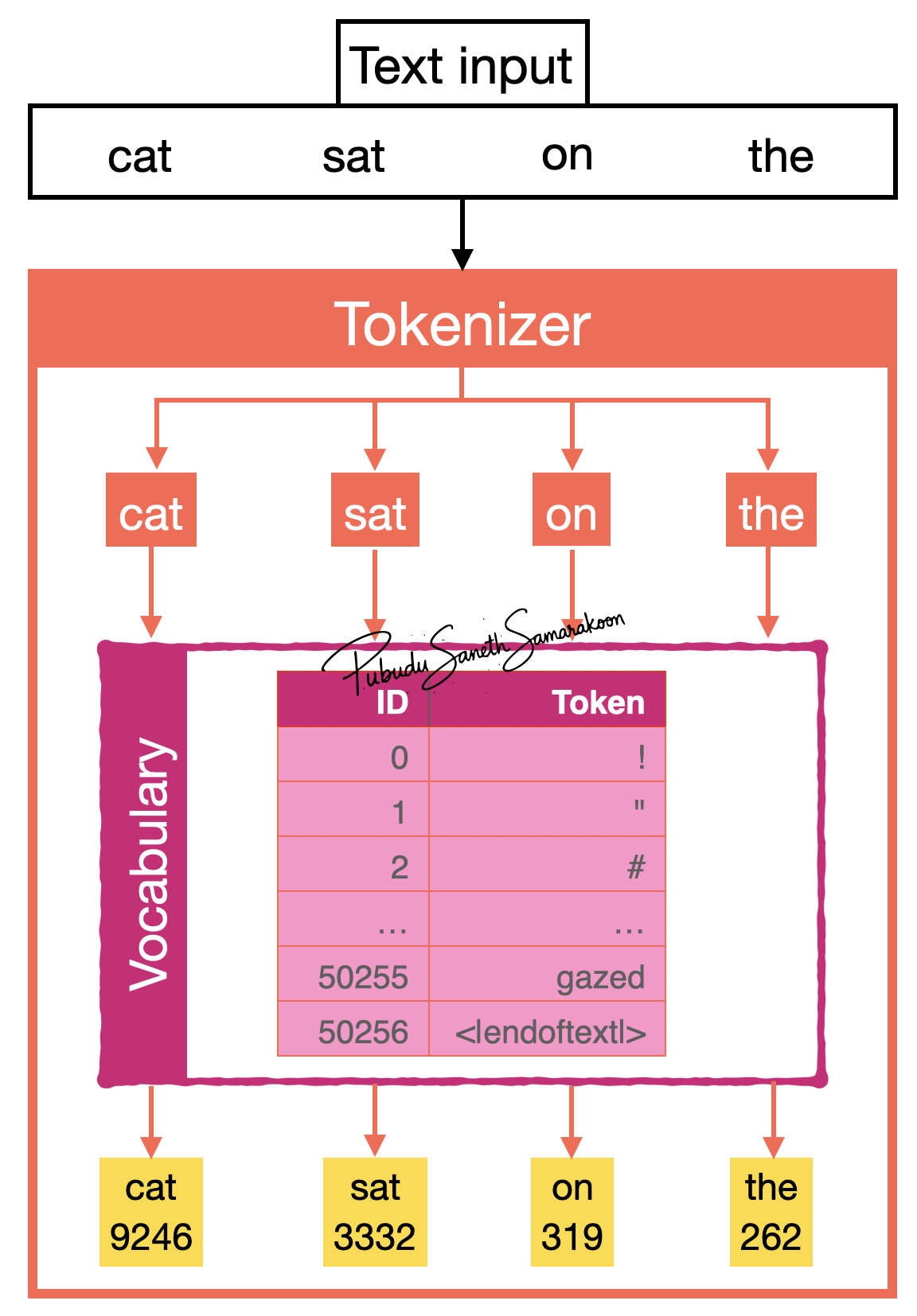
GPT-2 tokenizer
Text to Token-IDs
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
print(f"Length of the vocabulary: {len(tokenizer)}")
sentence = "cat sat on the"
token_ids = tokenizer.encode(sentence)
print(f"Token IDs of the sentence '{sentence}': {token_ids}")
decoded_sentence = tokenizer.decode(token_ids)
print(f"Decoded sentence: {decoded_sentence}")
Text to subword units
summarization_token_ids = tokenizer.encode("summarization")
print("Token IDs for word `summarization`:", summarization_token_ids)
print("Mapping of tokens to token IDs:")
for token_id in summarization_token_ids:
print(f"'{tokenizer.decode(token_id)}' -> {token_id}")
Output
Text to Token-IDs
Length of the vocabulary: 50257
Token IDs of the sentence 'cat sat on the': [9246, 3332, 319, 262]
Decoded sentence: cat sat on the
Text to subword units
Token IDs for word `summarization`: [16345, 3876, 1634]
Mapping of tokens to token IDs:
'sum' -> 16345
'mar' -> 3876
'ization' -> 1634